价格: 19 学币
分类: 爬虫
发布时间: 2021年12月8日 22:59
最近更新: 2021年12月19日 00:56
资源类型: VIP
〖课程介绍〗:
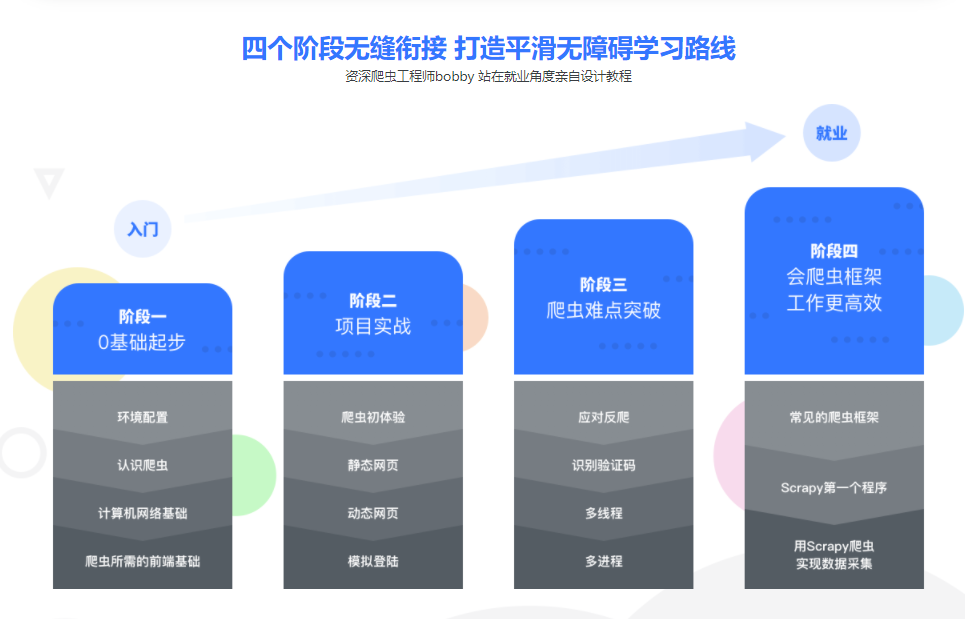
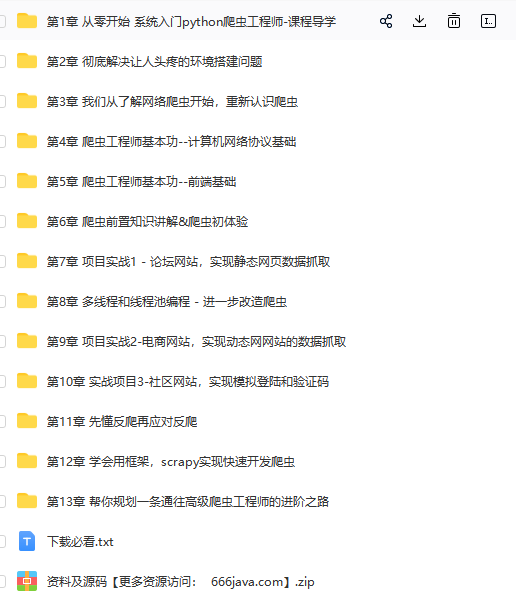
〖课程目录〗:
〖视频截图〗:
课程目录和资源目录截图在页面底部,有问题请联系客服微信(网站右侧)
客服微信